git源代码管理模型
声明:
本博客欢迎转发
内容系本人学习, 研究和总结,有些是摘抄自互联网,如有雷同,实属荣幸.
Git Flow 是什么
Git Flow是构建在Git之上的一个组织软件开发活动的模型,是在Git之上构建的一项软件开发最佳实践。Git Flow是一套使用Git进行源代码管理时的一套行为规范和简化部分Git操作的工具。
2010年5月,在一篇名为“一种成功的Git分支模型”的博文中,@nvie介绍了一种在Git之上的软件开发模型。通过利用Git创建和管理分支的能力,为每个分支设定具有特定的含义名称,并将软件生命周期中的各类活动归并到不同的分支上。实现了软件开发过程不同操作的相互隔离。这种软件开发的活动模型被nwie称为“Git Flow”。
一般而言,软件开发模型有常见的瀑布模型、迭代开发模型、以及最近出现的敏捷开发模型等不同的模型。每种模型有各自应用场景。Git Flow重点解决的是由于源代码在开发过程中的各种冲突导致开发活动混乱的问题。因此,Git flow可以很好的于各种现有开发模型相结合使用。
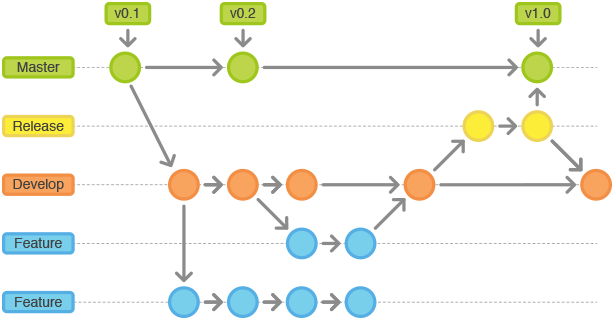
在开始研究Git Flow的具体内容前,下面这张图可以看到模型的全貌(引自nvie的博文):
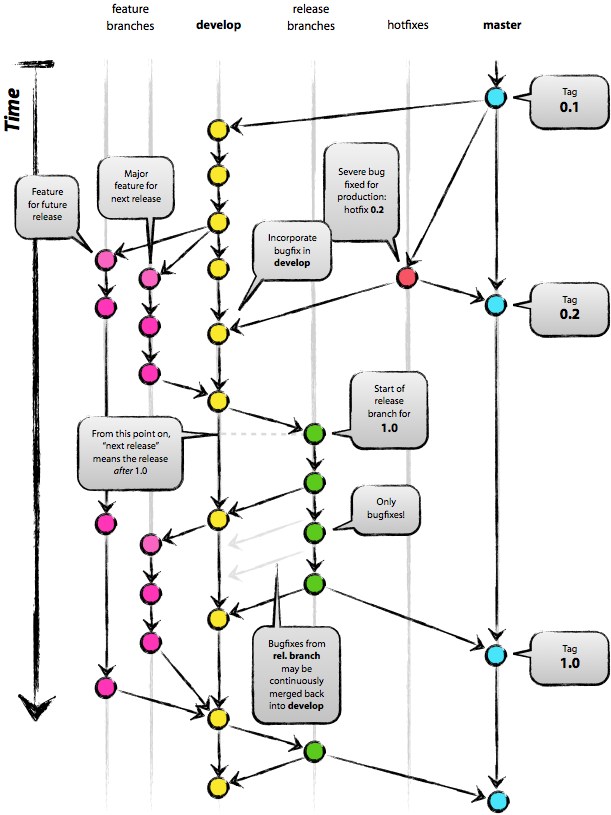
Git Flow 中的分支
Git Flow模型中定义了主分支和辅助分支两类分支。其中主分支用于组织与软件开发、部署相关的活动;辅助分支组织为了解决特定的问题而进行的各种开发活动。
主分支
主分支是所有开发活动的核心分支。所有的开发活动产生的输出物最终都会反映到主分支的代码中。主分支分为master分支和development分支。
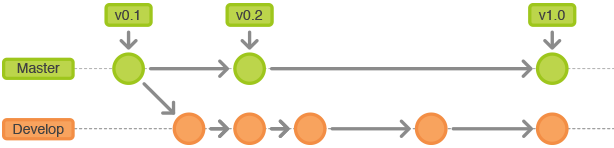
master分支
master分支上存放的应该是随时可供在生产环境中部署的代码(Production Ready state)。当开发活动告一段落,产生了一份新的可供部署的代码时,master分支上的代码会被更新。同时,每一次更新,最好添加对应的版本号标签(TAG)。
develop分支
develop分支是保存当前最新开发成果的分支。通常这个分支上的代码也是可进行每日夜间发布的代码(Nightly build)。因此这个分支有时也可以被称作“integration branch”。
当develop分支上的代码已实现了软件需求说明书中所有的功能,通过了所有的测试后,并且代码已经足够稳定时,就可以将所有的开发成果合并回master分支了。对于master分支上的新提交的代码建议都打上一个新的版本号标签(TAG),供后续代码跟踪使用。
因此,每次将develop分支上的代码合并回master分支时,我们都可以认为一个新的可供在生产环境中部署的版本就产生了。通常而言,“仅在发布新的可供部署的代码时才更新master分支上的代码”是推荐所有人都遵守的行为准则。基于此,理论上说,每当有代码提交到master分支时,我们可以使用Git Hook触发软件自动测试以及生产环境代码的自动更新工作。这些自动化操作将有利于减少新代码发布之后的一些事务性工作。
辅助分支
辅助分支是用于组织解决特定问题的各种软件开发活动的分支。辅助分支主要用于组织软件新功能的并行开发、简化新功能开发代码的跟踪、辅助完成版本发布工作以及对生产代码的缺陷进行紧急修复工作。这些分支与主分支不同,通常只会在有限的时间范围内存在。
辅助分支包括:
- 用于开发新功能时所使用的feature分支;
- 用于辅助版本发布的release分支;
- 用于修正生产代码中的缺陷的hotfix分支。
以上这些分支都有固定的使用目的和分支操作限制。从单纯技术的角度说,这些分支与Git其他分支并没有什么区别,但通过命名,我们定义了使用这些分支的方法。
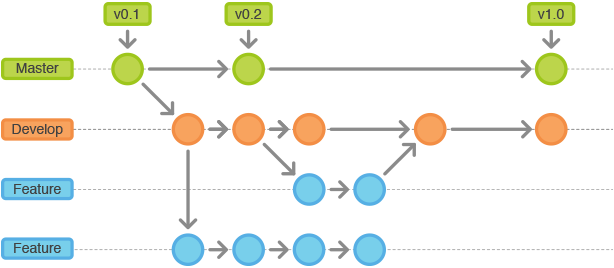
feature分支
使用规范:
可以从develop分支发起feature分支
代码必须合并回develop分支
feature分支的命名可以使用除master,develop,release-,hotfix-之外的任何名称
feature分支(有时也可以被叫做“topic分支”)通常是在开发一项新的软件功能的时候使用,这个分支上的代码变更最终合并回develop分支或者干脆被抛弃掉(例如实验性且效果不好的代码变更)。
一般而言,feature分支代码可以保存在开发者自己的代码库中而不强制提交到主代码库里
release分支
使用规范:
- 可以从develop分支派生
- 必须合并回develop分支和master分支
- 分支命名惯例:release-*
release分支是为发布新的产品版本而设计的。在这个分支上的代码允许做小的缺陷修正、准备发布版本所需的各项说明信息(版本号、发布时间、编译时间等等)。通过在release分支上进行这些工作可以让develop分支空闲出来以接受新的feature分支上的代码提交,进入新的软件开发迭代周期。
当develop分支上的代码已经包含了所有即将发布的版本中所计划包含的软件功能,并且已通过所有测试时,我们就可以考虑准备创建release分支了。而所有在当前即将发布的版本之外的业务需求一定要确保不能混到release分支之内(避免由此引入一些不可控的系统缺陷)。
成功的派生了release分支,并被赋予版本号之后,develop分支就可以为“下一个版本”服务了。所谓的“下一个版本”是在当前即将发布的版本之后发布的版本。版本号的命名可以依据项目定义的版本号命名规则进行。
hotfix分支
使用规范:
- 可以从master分支派生
- 必须合并回master分支和develop分支
- 分支命名惯例:hotfix-*
除了是计划外创建的以外,hotfix分支与release分支十分相似:都可以产生一个新的可供在生产环境部署的软件版本。
当生产环境中的软件遇到了异常情况或者发现了严重到必须立即修复的软件缺陷的时候,就需要从master分支上指定的TAG版本派生hotfix分支来组织代码的紧急修复工作。
这样做的显而易见的好处是不会打断正在进行的develop分支的开发工作,能够让团队中负责新功能开发的人与负责代码紧急修复的人并行的开展工作。